Site search functionality allows your visitors to search your website for specific content. All of content hosted on HubSpot is automatically indexed in HubSpot’s search engine.
Please note:Content beyond an HTML size of 2 MB will be trimmed before being stored in content search.
Searching Content
The search engine is accessible through the site search API. This API supports numerous filtering options to allow you to create a highly customized and powerful search experience on your website. For example, if you wanted to build a search into your blog, you can query for type=BLOG_POST to only return blog posts. Or, if you wanted to build search into the Spanish version of your website, you could query language=es to only return Spanish pages.
The API returns JSON that can be parsed with JavaScript to display the results on your website. All content types will return the page domain, title, url and language. The description returned is a sample of text from the content which best matches the search term. A <span class="hs-search-highlight hs-highlight-html"> element will wrap perfectly matching text, allowing you to highlight matching text with CSS.
Depending on the type of content searched, the results return slightly different information, so you can display results for unique content types differently. For example, blog posts will return information on which tags the post has, who the author is, and when it was published.
Implementing search on your website
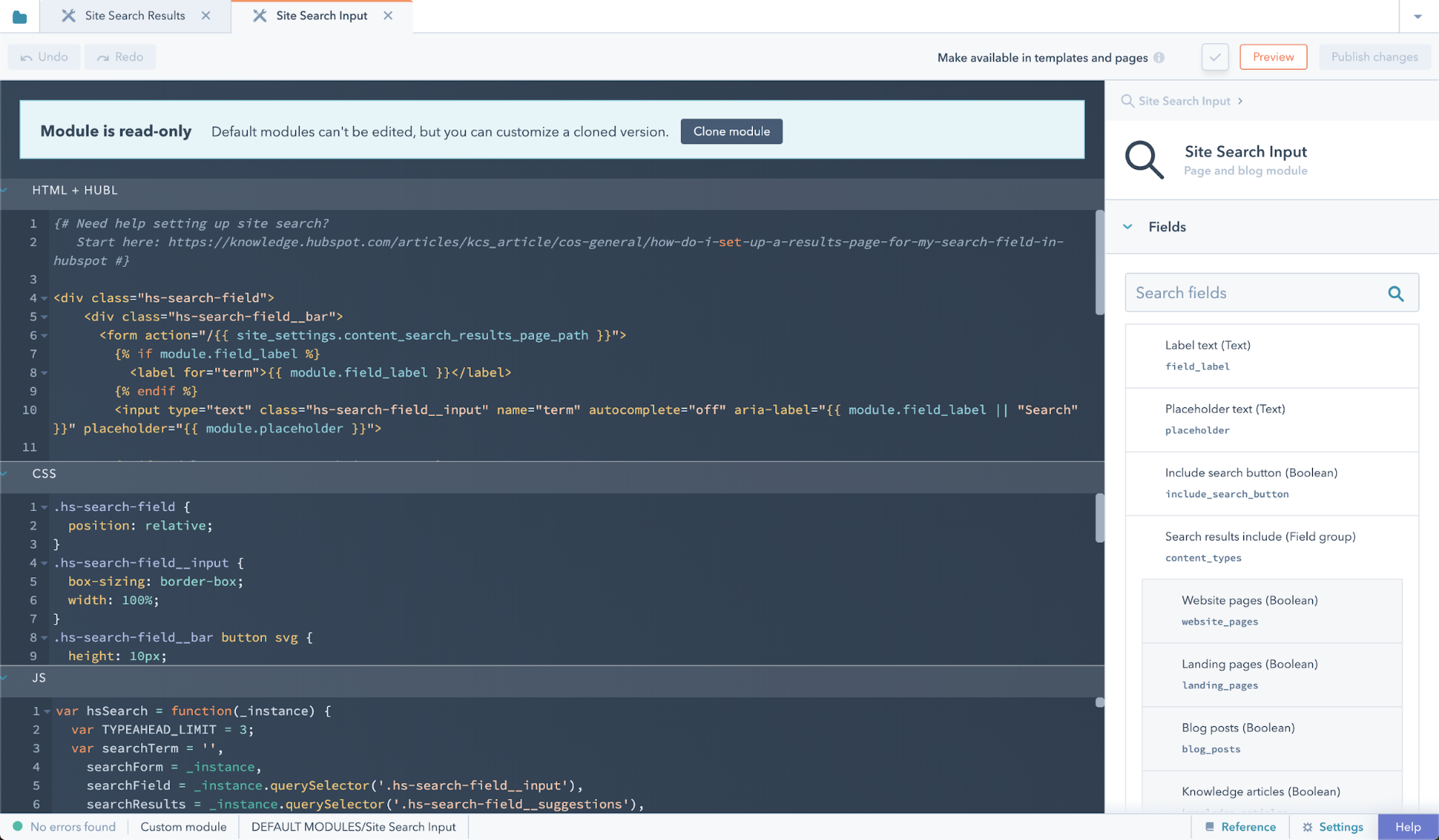
There are two default modules you can use to easily implement search on your website, which use the site search API: search_input and search_results.
An input field for visitors to enter search terms into. This module can exist anywhere on your website. This module can be included in a template with {% module "search_input" path="@hubspot/search_input" %}.
Site Search Results
Returns a listing of content based on the search term. This module can exist anywhere on your website. This module can be included in a template with
If the functionality of these modules is not how you want search to work on your website, you can build your own search modules or functionality. The default search modules are designed to be extended based on your search needs. You can view and clone these modules in the Design Manager by searching for their names in the Finder, or, you can fetch them to your local environment using the CMS CLI by running hs fetch @hubspot/search_input.module or hs fetch @hubspot/search_results.module.
Search Results Template
Every domain has its own search results page by default. The template and path for this page are set at Settings > Website > Pages under the System Pages tab for specific domains. See the CMS theme boilerplate search results template as an example. The domain set for the search results page is automatically connected to the default search modules. However, you can use the site search API to build our your search results as you’d like on any pages of your website.
How is the search precedence determined?
The order of search results is determined by a series of weighted comparisons of page content to the visitor’s search term. Page content is separated into comparison fields with varying weight based on where the content lives within the HTML of your pages. Comparison fields are grouped in order of weight:
- HTML title
- Meta description
- H1 HTML elements
- H2 HTML elements
- H3 HTML elements
- Other HTML elements
Please note that this list is subject to change.
If you wish to tell our indexer to specifically boost certain elements on a page, you can wrap the content in a hs-search-keyword class.
Control indexing during development
While developing a new site, it’s useful to be able to test site search without worrying about the site being indexed by search engines such as Google.
In your robots.txt you can tell HubSpot to crawl everything, while blocking other bots.
If any of your pages have a meta tag specifying no index, the page will still not be indexed, even if allowed in the robots.txt.Also remember to review your robots.txt prior to launch to ensure everything indexes how you want it to.
Default indexing behavior
Because the CMS knows the intent of certain types of pages, content search is able to safely limit indexing to allow indexing of content type pages. Examples of content type pages:
- Site Pages
- Landing Pages
- Knowledge articles
- blog posts
System pages and password protected pages are not indexed. CMS Membership restricted pages will only display in hubspot content search for users that are signed in and have access to the pages.
How can I exclude pages from being returned in search results?
If you block a page from being indexed to search engines via your websites robots.txt file or via meta tags, they will not be indexed for site search.
In your robots.txt add a disallow.
You can also add a NOINDEX, NOFOLLOW meta tag in the <head> at the page or template level.
You don’t need to block robots using both robots.txt and the meta tag. Doing so can make it confusing later if you decide to allow indexing of a page.
How to exclude sections of a page from being indexed in search
Sometimes there are regions of a page that are not useful to return in search results. This might be content from a header, a footer, sidebar, etc. When this is the case, you can add the class hs-search-hidden to your HTML for those regions to have search ignore the content inside.