In our first blog post, “Why ML Recommendations Matter: Building a Custom Solution with HubSpot and AWS,” we discussed the increasing demand for personalized customer experiences in B2C and B2B contexts. We also introduced a project demonstrating how HubSpot can be integrated with Amazon Personalize to create a custom recommendation engine for personalized product and content recommendations. The project architecture highlights two phases: Training and Inference. The Training phase involves data preparation and setting up foundational elements, while the Inference phase applies the trained model to generate actionable recommendations within HubSpot.
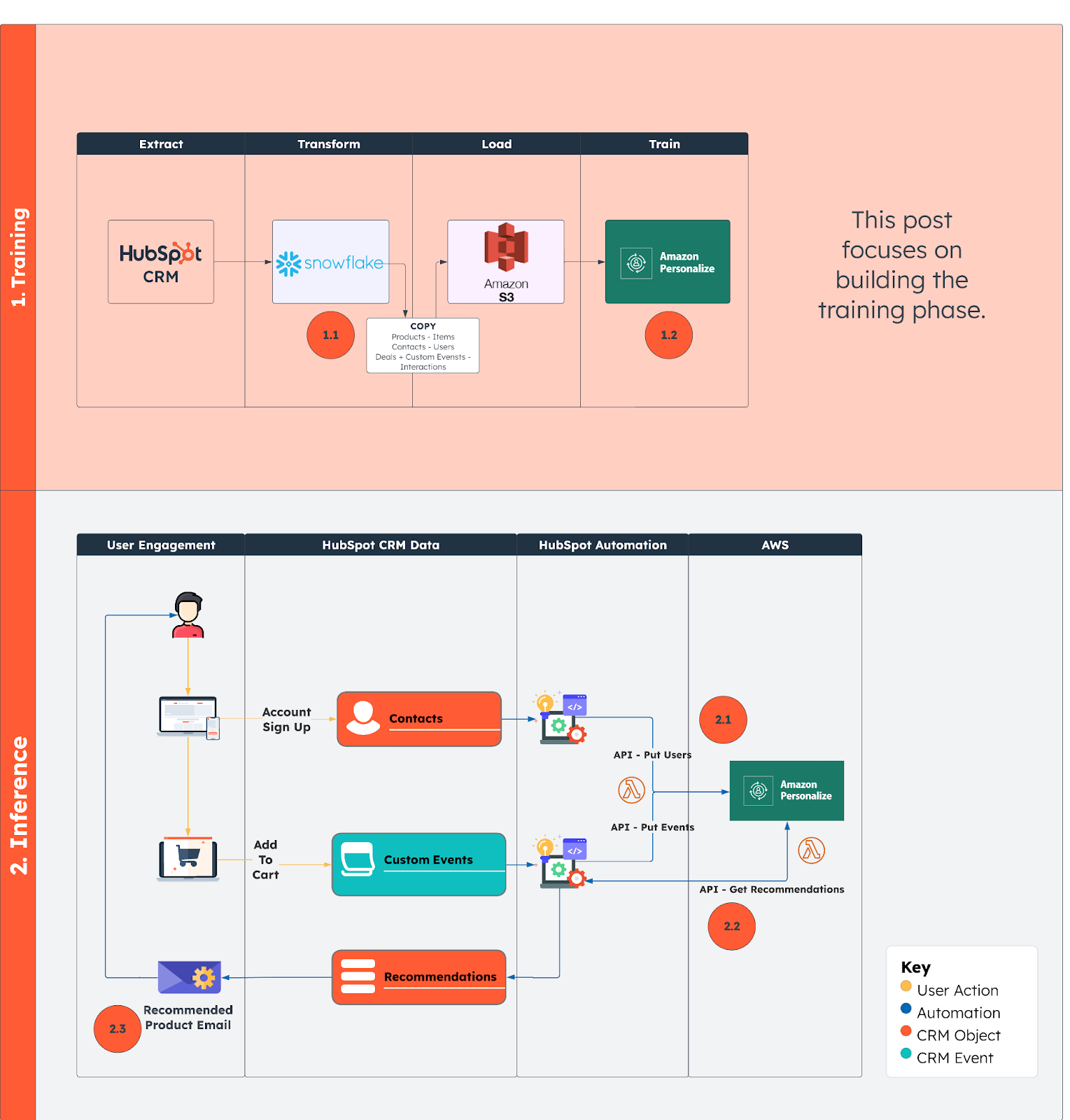
This post provides a tutorial for Phase 1: Model Training - illustrating the steps to create a customized model used for generating personalized recommendations. Model training is a critical stage for achieving accurate and effective ML-driven recommendations.
We begin with data preparation - modeling and importing sample data to HubSpot to represent website visitor interactions, product details, and user details. Then, we’ll leverage HubSpot’s Operations Hub Snowflake Data Share for easy ETL (extraction, transformation, and loading) between HubSpot & Amazon Web Services (AWS), where we’ll perform the model training in Amazon Personalize. In a real-world use case, your HubSpot instance will likely already have the requisite website interactions, product details, and user details, and the ETL can use other tools or HubSpot’s APIs.
Once the data is prepared, we use Amazon Personalize to train a custom model that learns from the behavioral data. This training process enables the ML model to understand patterns, user preferences, and behaviors essential for making personalized product recommendations.
Data preparation overview
The accuracy of ML models heavily depends on the quality of data. Data needs to be clean and structured, ensuring the model can accurately interpret user behaviors and preferences, leading to a more personalized and effective recommendation. Here’s an overview of the key objects needed for Training an Amazon Personalize recommendation model:
- Items (Products): These products sold in the eCommerce store represent HubSpot's Product CRM object.
- Users (Contacts): Represented as HubSpot Contacts, these are the store’s visitors and customers.
Note: Customer names are typically not recommended for ML recommendations and can create privacy issues.
- Interactions (Events & Deals): These are the actions users take, such as viewing a product, adding it to a cart, or making a purchase. HubSpot Custom Events are used to capture actions like "View" and "Add to Cart," while Deals represent completed purchases in HubSpot.
The data model below demonstrates how we’ll map HubSpot objects and events to Amazon Personalize data. For a complete data map, please refer to the GitHub repository outlining each property, its appropriate mapping, and the associated data files. Otherwise, please refer to the linked CVS files below in the prerequisites section.
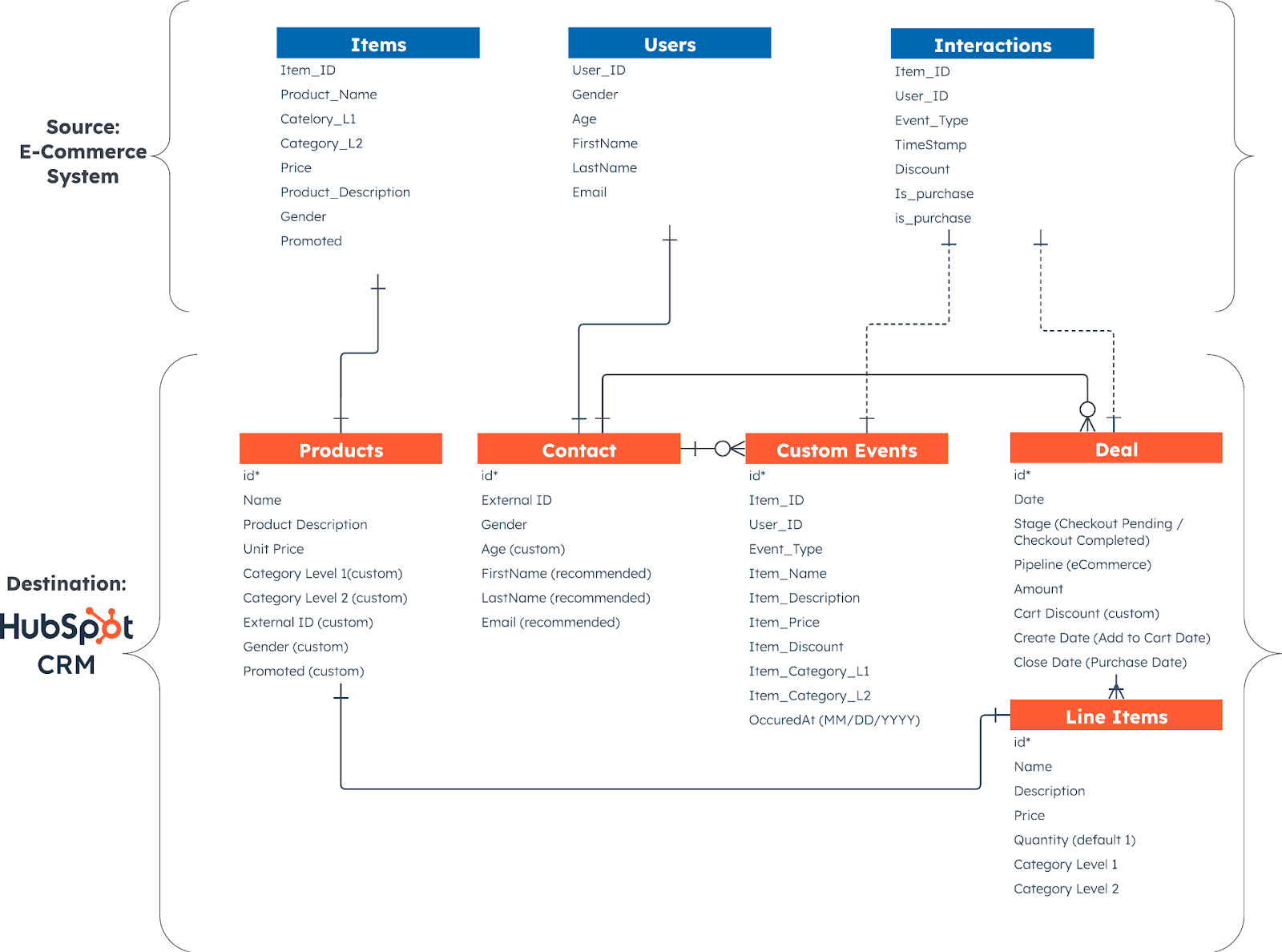
Follow our recommended data structure closely to ensure the model is trained correctly. To begin preparing your data for mapping, you can download sample data or use your own example data. Log in to your HubSpot account with admin access to get started.
Additionally, here are some helpful resources that explain how to implement a data model:
- Create & Edit Properties
- Custom Events
- Import Data in HubSpot
Prerequisites
This guide will help you through the training process to create a recommendation engine that delivers real business value.
We encourage you to follow along by referring to the following resources:
- GitHub repository: Contains all the necessary code samples, detailed instructions, and a complete list of technical prerequisites.
- Project phases: The repository is divided into two key phases:
Note: for this blog post, we will be focusing on the Training Phase.
- CSV files:
- Items
- Users/Emails
- Custom Event Interactions: all e-commerce interactions have been split into 5 dataset files, which helps with the volume of data imported within HubSpot
- Deals
- Snowflake queries: Contains queries for your data warehouse and HubSpot portal.
Implementation of this solution will require some investment across these different phases. Here is a brief breakdown of the associated costs:
- AWS usage fees: unless you leverage the AWS free tier for this project, we should note that there is a cost to hosting, storage, and API usage on AWS. Costs will vary depending on the horse the recommendation engine runs. Use the Amazon Personalize Cost Calculator to estimate expenses.
- HubSpot subscription costs: This solution leverages Operations Hub Enterprise and Sales Hub Enterprise.
Understanding these costs upfront can allow you to budget effectively, plan for impact or higher engagement, and improve conversions. For a more detailed breakdown of the technical requirements, visit the GitHub repository.
Step 1: Preparing data model in HubSpot
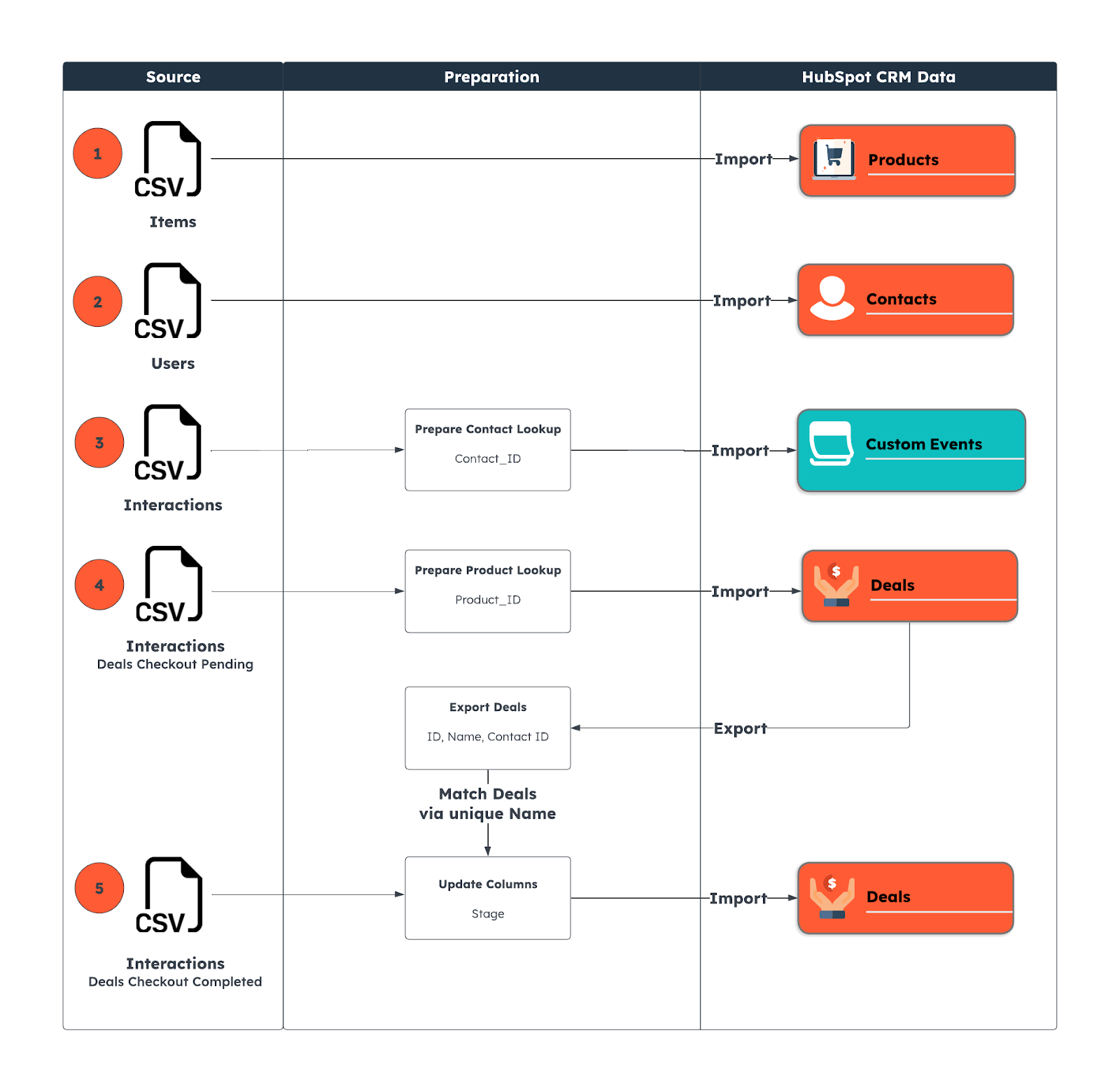
Fig. 3 shows the data preparation flow to stage training data in HubSpot that can be exported through Snowflake into AWS.
First, you’ll need to model your data in HubSpot and import it from the sample data we mentioned earlier or from your own data. We recommend using this Postman collection to create the object properties listed below, with the associated CSV files listed above or within the GitHub repository.
For more detailed written instructions, check out: Preparing the data model.
Create Product properties:
- Use Postman to create properties within the Product object. To manually create these properties, follow the Product properties instructions within GitHub.
Create Contact properties:
- Use Postman to create properties within the Contact object. To manually create these properties, follow the instructions for the Contact Properties within GitHub.
Create Custom Event Definition:
- Define events to track customer actions, such as page views or items added to the cart.
- Use Postman to create properties within the e-commerce Custom Event Definition. To manually create the Custom Event Definition, follow the instructions within GitHub.
Create Deal properties:
- Use Postman to create properties within the Deal object. To manually create these properties, follow the GitHub instructions for Deal properties.
- Deals in HubSpot will represent completed transactions. For example, a Deal could represent a Product added to the cart with the Deal’s stage = “Checkout Pending,” or a Deal could represent a Product purchased with the Deal’s stage = “Checkout Completed.”
Next, we’ll import the following data into HubSpot to ensure it is correctly structured for Amazon Personalize. Use the associated CSV files you can refer to in GitHub. There are two ways to import data within HubSpot: Postman Collection or HubSpot CSV Imports.
- Postman Collections [Recommended] - these are predefined scripts that import data from the CSV files into HubSpot using HubSpot APIs. The Postman approach would be less time consuming over manual CSV imports.
- HubSpot CSV Imports - the import tool within HubSpot can be used to import data from the CSV files. With this process there will be some degree of file preparation which is documented in detail within GitHub.
- Product Postman Collection to import the Products within HubSpot.
- Product HubSpot CSV Imports - Import the Items file into the HubSpot Products object, mapping the CSV columns to the correct HubSpot properties.
- Contact Postman Collection to import the Contacts within HubSpot.
- Contacts HubSpot CSV Imports - Import the Email/Users file into HubSpot Contacts object, mapping the CSV columns to the correct HubSpot properties.
- Custom Event Completions Postman Collection to import interactions within HubSpot. All e-commerce interactions have been split into 5 dataset files, which helps with the volume of data imported within HubSpot.
- Custom Event Completions HubSpot CSV Imports - Import the interactions from the 5 dataset files above (3.1) into HubSpot. Review the GitHub instructions to ensure that the appropriate Contact is associated with the Custom Event Completion.
- Deals Postman Collection to import the Deals within HubSpot.
- Deals HubSpot CSV Imports - Import the Checkout Pending Deals into the HubSpot Deals object, mapping the CSV columns to the correct HubSpot properties. Review the GitHub instructions to ensure the appropriate Contact and Product are associated with the Deal and Deal LineItems.
- Deals Postman Collection to import the Deals within HubSpot.
- Deals HubSpot CSV Imports - Import the Checkout Completed Deals into the HubSpot Deals object, mapping the CSV columns to the correct HubSpot properties. Review the GitHub instructions to ensure that the appropriate Contact is associated with the Deal and the appropriate Deal is updated as Checkout Completed. A unique lookup will be required to update the existing HubSpot Deals with the new stage.
Following this structured approach ensures that HubSpot's CRM data is well-prepared for exporting through Snowflake and integrated with Amazon Personalize for training a recommendation model.
Step 2: Training data from HubSpot to Snowflake to Amazon
To efficiently train a recommendation model with Amazon Personalize, export, and prepare your HubSpot data for machine learning. HubSpot’s Operations Hub Enterprise allows easy access to its entire data model via the Snowflake Data Share, making it the recommended approach for large-scale data extraction, especially for complex interactions such as “Add to Cart” (custom events) and purchase data (HubSpot Deals).
To aid you in deploying the training phase in AWS, we’ve prepared several queries for data extraction and automated AWS CloudFormation templates that do much of the AWS heavy lifting for you. Suppose Snowflake is not part of your technology stack, and you wish to continue with the Amazon Personalize Training Phase. In that case, you can utilize the CSV data files and skip to the “Launch Amazon Personalize MLOps stack” step below.
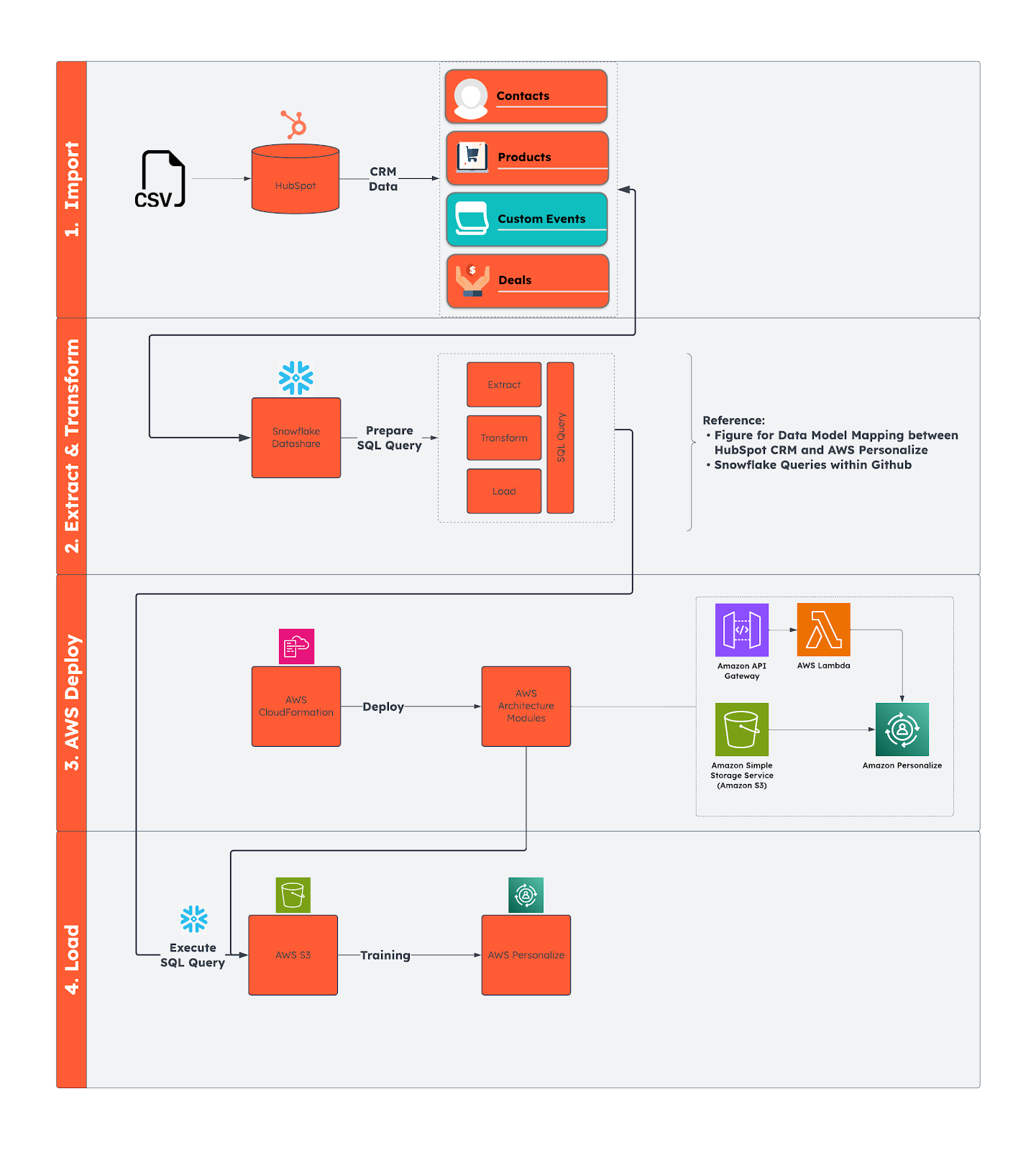
Fig. 4 represents the data flow from HubSpot CRM to AWS through Snowflake.
For detailed information or references regarding this step, please refer to the GitHub repository, which contains applicable links and code samples.
Enable Snowflake data share in HubSpot:
- If your HubSpot account includes Operations Hub Enterprise, enable the Snowflake Data Share to begin querying and exporting data.
- Contact your HubSpot representative to explore a trial if this isn't enabled.
Launch Amazon Personalize MLOps stack:
- Launch the Personalize MLOps stack using AWS CloudFormation. This automates setting up the infrastructure for your recommendation model.
- This stack will create a default S3 bucket based on the name of the Personalize name provided during the MLOps stack creation. However, you can use an existing bucket by using the bucket name and updating the Personalize Configuration file. Reference this bucket in the next step.
- Once the stack is created, upload your customer datasets and the Personalize configuration file (JSON) to the appropriate folder in the Personalize Bucket in S3 (e.g.,
s3://<personalize_bucket_name>/train/{file_name.csv}/).
Export HubSpot data to Amazon S3:
When exporting Hubspot data, you can leverage Snowflake or the CSV files.
Use Snowflake- Configure Snowflake - set up Snowflake to export data from HubSpot to Amazon S3:
- Create an IAM user in AWS with S3FullAccess permissions or specific bucket access.
- Generate an Access Key and Secret Key for Snowflake to connect to your S3 bucket.
- Run test queries in Snowflake to extract data from HubSpot’s CRM, including events like “Add to Cart” and purchase records.
Note: As mentioned above in the prerequisites section, you can refer to these Snowflake queries within the GitHub repository.

- Modify these queries to fit your specific data needs, and configure Snowflake to unload the extracted data into your S3 bucket.
Use the CSV files below to upload to your S3 bucket
hs-contacts.csv,hs-interactions.csv,hs-items.csv
Train the model:
- The figure below represents the HubSpot Data Model mapping to Amazon Personalize Data Model. The Amazon Personalize Data Model requires Users, Items, and Interactions to process, train, and generate recommendations.

Fig. 5 illustrates the data mapping between HubSpot CRM objects and Amazon Personalize.
- After uploading the data, the model training begins automatically using the provided datasets. The training status can be monitored via the Amazon Personalize UI.
Use Personalize APIs:
- The Amazon Personalize MLOps stack should create a set of APIs using AWS API Gateway and AWS Lambda to interact with the recommendations programmatically. Navigate to API Gateway and find the endpoints.
- These APIs will be leveraged in the next phase of the tutorial for integration with HubSpot workflows.
Recap of the Training phase
In this post, we explored the Training Phase of building a custom recommendation engine with HubSpot and Amazon Personalize. This training process ensures that your recommendation engine is equipped with the insights needed to understand patterns in customer interactions, setting the stage for generating valuable, personalized experiences for your users.
In the next blog post, we will review the Inference Phase, where the Amazon Personalize model is used to generate recommendations. Once operational, Amazon Personalize can offer personalized suggestions based on real-time user interactions in HubSpot.
These recommendations will be utilized within HubSpot in two key ways that we’ll demonstrate for you:
- Automating personalized emails that include product recommendations
- Create a custom card UI extension that allows sales and marketing teams to generate and view recommendations manually and attach them to deals.
This integration will show you how you can enhance the user experience while empowering your team with powerful tools to engage customers and drive conversions. Stay tuned for the next phase of this project!
 Robert Ainslie, Manager, Solution Architecture, HubSpot
Robert Ainslie, Manager, Solution Architecture, HubSpot Amit Das, Senior Solutions Architect, HubSpot
Amit Das, Senior Solutions Architect, HubSpot