Supported products
Supported products
- If you have a Content Hub Professional or Enterprise subscription, you can use GraphQL to fetch data for website pages.
- If you have a Sales Hub or Service Hub Enterprise subscription, you can use GraphQL to fetch data for UI extensions.
Advantages of using GraphQL
The GraphQL API provides a single, unified way to fetch data from different data sources to power your website pages, instead of having to process and aggregate data from disparate REST API endpoints. You can specify the data within GraphQL queries, which allows you to decouple how you’re fetching data from the presentational layer of your template and module code. You can then include queries as part of your theme, or connect them directly to your modules, templates, and pages.GraphQL schema and queries
In HubSpot, the GraphQL schema describes the data sources you’re fetching from and the underlying data types available to your HubSpot account. This schema is auto-generated and will automatically update if you add custom properties, create custom objects, or associate object types. You can construct GraphQL queries to fetch data by traversing the schema from your HubSpot account. This approach allows you to specify the data you need for a given page on your website. Each GraphQL query consists of a tree of nested fields:- Root query field: the top-level field of your query that represents your data source. The available data sources are:
- CRM: records (e.g., contacts, companies, etc.) and other data from your CRM.
- HUBDB: data from a HubDB table.
- BLOG: data from blog posts, authors, and tags.
- KB: data from your knowledge base, including articles, categories, and tags.
- Child fields: based on the data source in your root query field, you can then specify the child fields you want to fetch, along with any associated properties.
Query data from your CRM
To query data from the HubSpot CRM, includeCRM as a root query field, then enter a data type as a child field. You can include any of the following data types from the CRM:
- Standard and custom objects
- Engagements, including calls, tasks, meetings, and notes
- Products and line items
- Quotes and subscriptions
- Marketing events
_collection to retrieve a list of objects of that type. You can provide arguments to a query field to fetch a single object or filter a collection of objects.
- Fetch a single instance: if you’re fetching a single instance like an individual contact record, specify one of the object’s properties and its associated value by including the property’s name as the
uniqueIdentifier, and the property’s value as theuniqueIdentifierValue. For example, the following query would fetch a contact with an ID of 753:
- Fetch and filter a collection: to fetch a collection of instances, add
itemsas a child field. To filter the objects in the response, include thefilterargument, then provide a map of filter operators to their associated values. A filter operator consists of the property you want to filter by, followed by a suffix. For example, the query below would fetch and filter a collection of contacts with hubspot.com email addresses:
- Add properties to fetch: enter the internal name of a property to include it in the response of your query. Both default and custom properties are supported.
- Include associations to other data types: you can also add a collection of instances of a data type associated with the parent data type, such as the companies associated with a contact. To add data from an associated data type:
- Include
associationsas a child field of the original data type you entered. - As a child field of
associations, enter the association you want to include by following the naming scheme of{ASSOCIATED_DATA_TYPE}_collection__{LABEL_SUFFIX}.- The associated data type can be a built-in association with a standard object, or an association with a custom object. Any associations to custom objects will be prefixed by
p_. - For primary associations, the label suffix is
primary. If you created a custom association label, the label suffix will be lower-cased, with each word in the label separated by an underscore. For example, if your custom association label is My custom association label, the label suffix would bemy_custom_association_label. - For example, if you had a custom object named House associated with the contact object, the association you’d include in your query would be p_house_collection__house_to_contact.
- The associated data type can be a built-in association with a standard object, or an association with a custom object. Any associations to custom objects will be prefixed by
- Add
itemsas a child field of your association, then include any properties you need from each item in the collection.
- Include
Query data from HubDB
To query data from HubDB, includeHUBDB as a root query field, then enter the name of a table to retrieve a single row from that table, or enter a name followed by _collection to retrieve multiple rows from that table.
You can provide arguments to a query field to retrieve a single row or filter multiple rows from the table:
- Retrieve a single row: if you’re retrieving a single row from a table, specify one of the table’s columns as the
uniqueIdentifierthen provide the associated value of the row you want to retrieve as theuniqueIdentifierValue. For example, the following query would retrieve a row from an executives table with a role of CEO:
- Retrieve and filter multiple rows: to fetch multiple rows from a table, add items as a child field. To filter the rows in the response, include the filter argument to your query field, then provide a map of filter operators to their associated values. A filter operator consists of the property you want to filter by, followed by a suffix. For example, the query below would retrieve and filter rows from the executives table whose role contains O__fficer:
- Add columns to retrieve: enter the name of a column to include it in the response to your query. If one of your columns is a foreign ID and you want to include columns from the associated table:
- Include
associationsas a child field ofitems. - As a child field under
associations, enter the name of the foreign table with the_collectionsuffix, followed by two underscores and the name of the foreign ID column. For example, if the foreign ID column is recent_posts, and the name of the foreign table you want to reference is blog_posts, then the resulting field to include in your query would beblog_posts_collection__recent_posts. - Add
itemsas a child field of the foreign table field you just entered, then include any columns you need from the foreign table. For example, to include additional columns from the executives table from the csuiteExecutives query above, along with the title and link from a blog_posts foreign table, you’d update the query to the following:
- Include
- Include metadata fields: internal properties of the table, such as the ID or the timestamp of the last update to a row, are prefixed with
hs_.
Retrieving data from child tables
If you’ve configured dynamic pages to be created from your HubDB tables, you can include data from child tables in your GraphQL query.- Add
hs_child_table_collectionas a child field of theitemsof the parent table collection. - For each child table that you want to include, include a nested child fragment, which consists of the spread operator (i.e.,
...) combined with a type condition, which includes theonkeyword and the name of the child table collection. For example, if you wanted to update thecsuiteExecutivesquery from above to include columns from theteamandrecent_postschild tables:
Retrieving unpublished data from a table
You can include unpublished data from a table by providing{draft: true} as a query argument to the name of the table that you’re retrieving. If you’ve added new columns since you last published the table, they will not be included.
Query blog data
To query blog data, includeBLOG as a root query field, then enter a data type as a child field. You can include any of the following data types:
- Post and post collection
- Author and author collection
- Tag and tag collection
- Retrieve a single blog post: retrieve the title and content of a single blog post by using its ID as the
uniqueIdentifier.
- Retrieve blog author fields from a post: retrieve the title and content of a single blog post, along with the blog author’s name and email address, by using its ID as the
uniqueIdentifier.
- Retrieve a filtered collection of blog posts: retrieve a set of blog posts filtered by the post title.
- Retrieve drafted blog posts: retrieve a collection of blog posts that are not currently published by specifying
draft: true.
Query knowledge base data
To query knowledge base data, includeKB as a root query field, then enter a data type as a child field. You can include any of the following data types:
- Knowledge base and knowledge base collection
- Articles and article collection
- Category and category collection
- Tag and tag collection
- Retrieve a single knowledge base article: retrieve the title and content of a single knowledge base article by using its ID as the
uniqueIdentifier.
- Retrieve a filtered collection of knowledge base articles: retrieve a set of articles filtered by the article title.
Test and run queries interactively using GraphiQL
You can test queries by using GraphiQL, which is an open-source tool that allows you to run queries interactively and explore which fields are available.- In your HubSpot account, navigate to the GraphiQL tool.
- In the left pane, create and edit your query by specifying the objects and their associated fields you’ll need for your website pages.
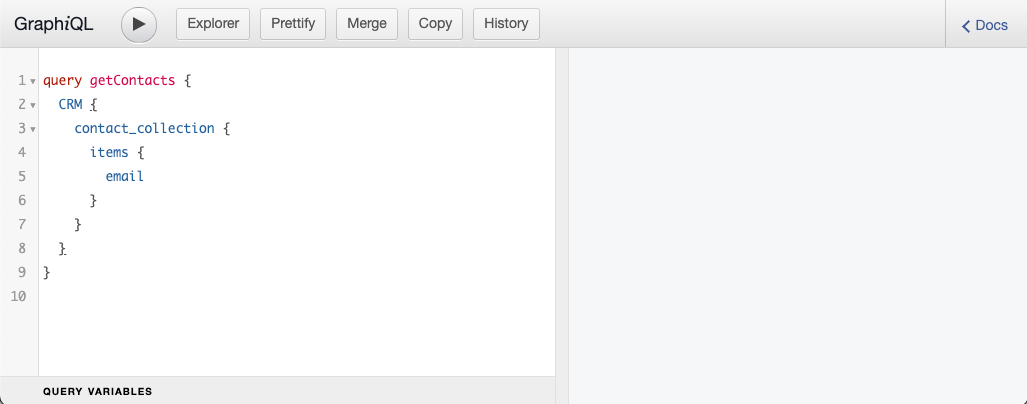
- To view all available data types, properties, and filters, click Explorer at the top of the page to toggle the Explorer view, which will list all available data types and their associated properties.
- Click a data type to automatically add it to your query and view all its associated properties.
- Select the checkbox next to a property to add it to your query.
- If you’re writing a query and you’re entering an argument for one of your fields, the Explorer pane will auto-populate a list of available filters.
- When you’re ready to test a query, click the play icon at the top of the page. The query’s response will appear in the right pane.

Filter and refine query results
You can provide arguments to a collection field in your query to filter, order, or paginate the objects returned in the response. The table below lists the supported arguments:Query argument types
Create a filter by combining a HubSpot property with a suffix that corresponds to a logical or mathematical operator, separated by two underscores (e.g.,
email__contains or name__eq). The supported operators are shown in the table below:
Paginating results
By default, if thelimit field isn’t included in your query, the maximum number of items returned in the results will be 10. You can increase this limit by providing the limit query argument within the parantheses following the collection name of your query, subject to the data source maximums described in the table above.
You can also provide the offset query argument within the parantheses of your query collection name, which specifies the index from which to start fetching items.
For example, the following query would start fetching results from an index of 10 and continue until the query’s limit of 30 is reached:
offset, limit, and total fields within the query itself, these values will be returned in the results, which can help you make any additional queries for any remaining data.
Combine multiple filters and use conditional logic
You can combine multiple filters in your query by defining filter groups. Each filter group is defined with curly brackets (e.g.,{}), and the filters within the resulting group will be ANDed together.
Use OR logic when querying CRM data
If you’re querying for CRM data, you can apply OR logic to a list of filter groups using theOR operator, followed by a list of comma-separated filter groups within square brackets (e.g., []).
For example, if you want to filter a list of Job custom objects to include records with a status of either “full-time” OR “contract”, then the resulting filter would be:
OR together must be specified as a separate filter group, even if the filter name is the same (i.e., status__eq in the example above).
The same format would apply if you want to OR together different filter types. For example, if you want to filter job records to include jobs with a “full-time” status OR jobs in the department “engineering”, then the resulting query would be:
AND logic of filters within a filter group with the OR logic between different filter groups to create more complex filters.
For example, if you wanted to represent the following logical expression as a GraphQL filter:
status="full-time" AND ((department="engineering" AND salary >= 80000) OR (department="sales" AND salary>=100000))
The resulting filter argument in your query would be:
Query complexity and account limits
To ensure optimal performance for querying your data, HubSpot enforces several limits on your queries, including a limit on the maximum items returned in a single query, as well as the aggregate complexity of your GraphQL queries.Limit on maximum items returned in a query
Individual GraphQL queries that retrieve CRM data are subject to a limit of 500 items returned in a query (e.g., up to 500 contacts can be retrieved in an individual query). There is no maximum limit to retrieving rows from a HubDB table. Learn more about manually specifying a custom limit to the items returned in your query using thelimit field in the Query argument types table above.
Query complexity and account limits
HubSpot also enforces aggregate complexity limits, based on factors such as the total number of objects and their associated properties in your query. Likewise, since HubSpot needs to make a new internal API request for each top-level object, complex queries with nested associations incur an additional cost to execute. The following factors are assigned point values and used to calculate a resulting complexity score:- Internal API request: 300 points
- Object retrieved: 30 points
- Requested property with a value: 3 points
- Requested property without a value: 1 point
- Points used for
contact_collection:- One internal API request is made (300 points).
- 10 contacts are retrieved (10 * 30 = 300 points).
- For each contact, five properties with values are retrieved (10 * 5 * 3 =150 points).
- Total points: 750
- Points used for
company_collection__primary:- One internal API is made per contact retrieved, totaling 10 requests (10 * 300 = 3,000 points).
- Six companies are retrieved (6 * 30 = 180 points).
- Five properties are retrieved with a value per company (6 * 5 * 3 = 90 points).
- One property is returned with no value per company (6 * 1 = 6 points).
- Total points: 3,276
- Points used for
ticket_collection__primary:- One internal API request is made per company per contact retrieved (10 * 6 * 300 = 18,000 points).
- 15 tickets are returned (15 * 30 = 450 points).
- Seven properties are returned with a value per ticket (15 * 7 * 3 = 315 points).
- Total points: 18,765
- Each individual query has a maximum of 30,000 points available. If this limit is reached while the query is running, all further execution is blocked and all object instances fetched up to that point are returned.
- Each HubSpot account is allowed up to 500,000 points per rolling minute and 300,000,000 total available points per rolling day when using the GraphQL API endpoint.
- If either of these limits are reached, further requests to the endpoint will receive an HTTP status code of
429 Too Many Requests. The only exception is that templates and modules with GraphQL queries loaded by site visitors will continue to function to preserve website user experience. - All other ad-hoc uses of the endpoint will no longer function (e.g., during template/module development, using the GraphiQL UI, and UI extensions using GraphQL queries).
- Accumulated points from the previous rolling period are not carried over to the next.
- If either of these limits are reached, further requests to the endpoint will receive an HTTP status code of
- The normal burst limits detailed in HubSpot’s API usage guidelines are not applicable to querying data using GraphQL.
extensions field.
- The complexity score for the query you provided in your request will be broken down within the
query_complexityfield. - If you’re using the external GraphQL API endpoint, the extensions field will also include account limit information within
rate_limit_info.
Use a GraphQL query in an API request
In addition to using GraphQL in your website pages, you can also use a GraphQL query in your integration, a Jamstack site, or in a custom code action in the workflows tool to specify the data you need from HubSpot without having to make separate requests to multiple API endpoints.Scope requirements
To make an API request to the/collector/graphql endpoint, the following scopes are required:
crm.objects.contacts.read scope is required if you’re fetching contacts in your query.
Make an API request to the /collector/graphql endpoint
Once a user has authorized the required scopes above, you can make aPOST request to the /collector/graphql endpoint and include the following fields:
For example, if you created a House custom object, and you wanted to query for a collection of House records in Miami, the request body would contain: