
In the realm of software development, Application Programming Interfaces (APIs) serve as the critical bridges that facilitate communication and data sharing between disparate software systems. However, the efficiency of this communication can significantly impact the overall performance of the system. Excessive API requests can lead to slower response times, increased server load, and a greater likelihood of hitting API rate limits. This article explores a case study where we optimized the process of querying data using HubSpot's API. We transformed an initially inefficient process into a streamlined, effective one, demonstrating how thoughtful API utilization can dramatically improve system performance.
The Challenge: Retrieving Open Tasks Efficiently
In a recent project, I was confronted with an intriguing problem: I needed to extract all open tasks for a specific company and all its associated contacts. Considering that a company could have up to 100 contacts and each contact or company could have between 0 and 50 tasks, the challenge was finding an efficient way to accomplish this without unnecessary data retrieval.
Initial Solution: An Unoptimized Approach
My initial approach involved using the Associations API to pull all contacts for the company, then using the same API to pull associated tasks for these contacts. I stored all the task IDs returned in an array for later use. I used the Associations API one last time to get all tasks for the specific company and appended the returned IDs to the tasks array. Finally, I used the Tasks API to pull each task and, if it was open, added it to another array for just the open tasks.
This approach, however, resulted in a large number of requests:
- Use the Associations API to pull all contacts for the company = 1 request.
/crm/v4/objects/company/{companyId}/associations/contacts - Use the Associations API to pull associated tasks for the contacts. Put all the task ids returned in a simple array to be used later = 100 requests.
/crm/v4/objects/contact/{contactId}/associations/tasks - Use the Associations API one last time to get all tasks for the particular company, append the returned ids to the tasks array = 1 request.
/crm/v4/objects/company/{companyId}/associations/tasks - Finally use the tasks api to pull each task and check if it's open, if it is add it to another array for just the open tasks = (between 0 and 50 tasks per object = 25 * 101 (100 contacts + 1 company)) = 2525 tasks.
/crm/v3/objects/tasks/{taskId}
The total number of requests amounted to 2627.
Problem Analysis: Over-fetching and Excessive Requests
Upon reviewing this approach, two major issues became apparent: over-fetching and excessive requests. In step 1, we fetched all contacts regardless of whether they had any tasks or open tasks. This inefficiency could not be resolved using the current approach of the Associations API. The most significant issue, however, was in step 4, where we made a staggering 2525 requests.
Optimizing with HubSpot Batch API:
A significant optimization was achieved using the BATCH API (/crm/v3/objects/tasks/batch/read), which allows up to 100 tasks per call. This reduced the requests for step 4 down to 26 - a substantial improvement. However, it's worth noting that this still resulted in pulling all tasks associated with the contacts and company, even if they were closed.
Further Optimization: Managing 2nd Degree Associations
- Another significant issue was in step 2, where we pulled all tasks for the associated contacts - amounting to 100 requests. The optimization here was tricky because HubSpot doesn't have an API that lets you pull 2nd degree associations (companies -> contacts -> tasks). However, using the BATCH read associations API (
/crm/v4/associations/contacts/tasks/batch/read), which allows up to 11,000 id inputs at a time, we were able to cut the number of requests to just 1.
Final Optimization Result: From 2627 to 31
The final number of requests was thus:
- Use the Associations API to pull all contacts for the company = 1 request.
/crm/v4/objects/company/{companyId}/associations/contacts - Use the associations api to pull associated tasks for the contacts. Put all the task ids returned in a simple array to be used later = 1 request (with potential pagination, so let's assume 3 requests).
/crm/v4/associations/contacts/tasks/batch/read - Use the associations api one last time to get all tasks for the particular company, append the returned ids to the tasks array = 1 request.
/crm/v4/objects/company/{companyId}/associations/tasks - Finally use the tasks api to pull each task and check if it's open, if it is add it to another array for just the open tasks = 26 requests.
/crm/v3/objects/tasks/{taskId}
Search API and the it’s usefulness for over-fetching
However, there's still room for improvement as we are still fetching all the tasks associated with the contacts and the company, even if they're closed. A solution for this would be to use the search api with the search through associations parameter.
The request for step 3 would look like this:
This would return all tasks that are associated with the company and are in the
NOT_STARTED state. Unfortunately we can't do the same thing for step 2 due to the number of contacts we want to fetch (the max it would support is 3). But that at least helps fix part of the over-fetching issue (1%).
Working within the boundaries of the HubSpot API, we managed to significantly enhance the initial request process. We transformed an overwhelming 2627 requests into a manageable 31 - a remarkable 98% improvement. This was achieved by strategically implementing the batch read and search through association features.
The optimization process significantly improved efficiency and reduced the risk of hitting API rate limits, thereby enhancing overall performance. However, there's another strategy that could potentially further minimize the number of requests - GraphQL.
Utilizing GraphQL to query the data
GraphQL provides a platform for users to query for specific data, nested data, and apply necessary filters, thus providing an even greater level of control over the data fetched.
HubSpot announced its support for GraphQL in late 2022, offering an exciting new avenue for data querying. This has quickly become my preferred method for querying HubSpot data. Let's illustrate this by setting up a request to retrieve these tasks:
The query above gets all tasks associated with the company that aren't associated with any contacts, where the task isn't completed. At the same time, it also gets all of the contacts associated with the company, and gets all of the incomplete tasks associated with any of those contacts. By implementing this solution, the number of API requests significantly decreases to just one, greatly enhancing the efficiency and overall performance of the solution.
In summary, the optimized solution using GraphQL provides a more effective way to query the required data, reducing the number of requests and enabling greater control over the data fetched. This optimization makes the process of retrieving open tasks for a company and its contacts more efficient and practical in the long run.
However, it's worth noting that this solution doesn't entirely resolve the over-fetching problem in step 2 (we're still pulling every contact, even if they don't have an open task). To address this, we'll introduce a single property at the contacts level. This is a score property called Any Open Tasks, which assigns a score of 1 to the contact if they have any associated activity without the task status of deferred or completed.
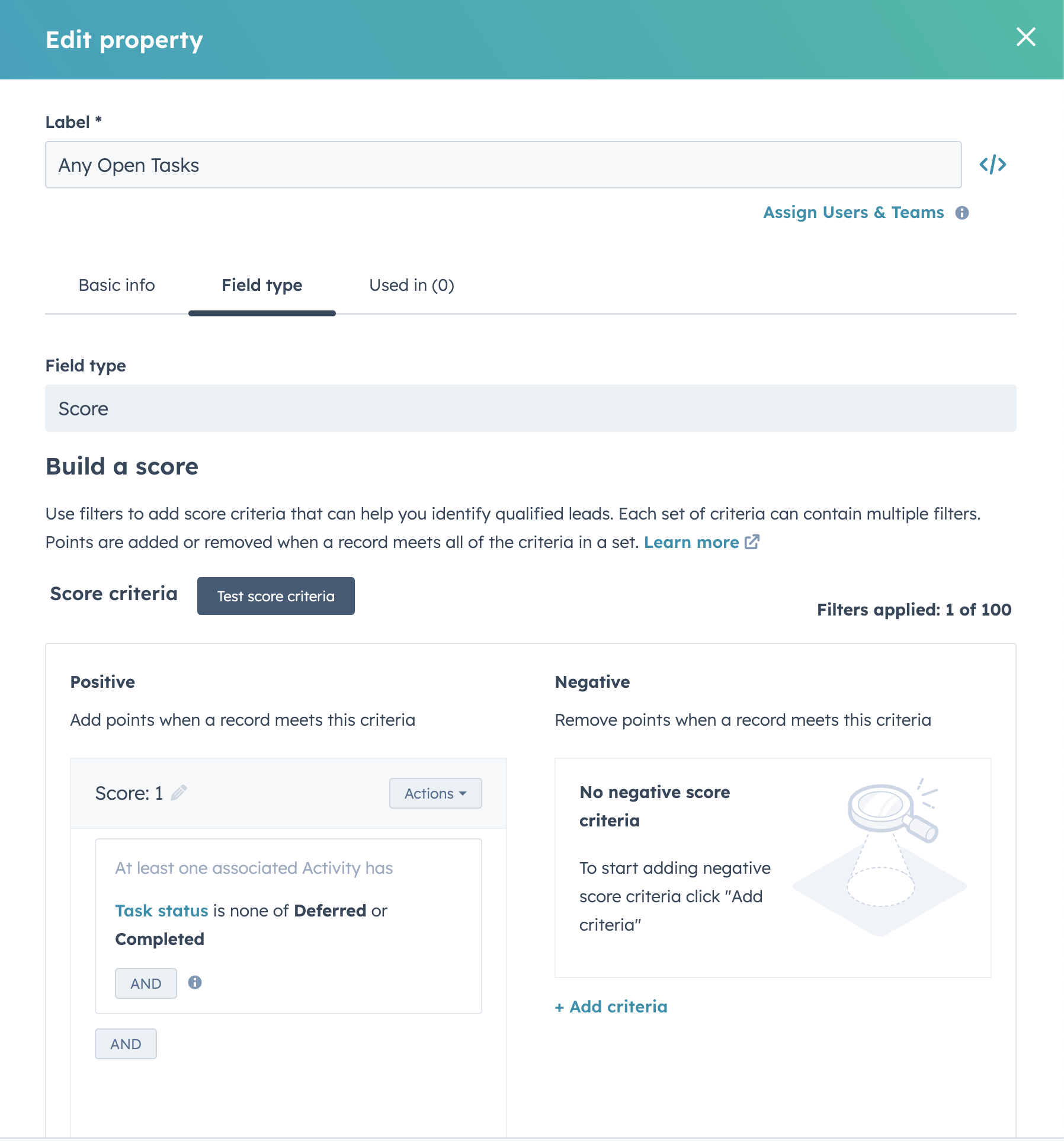
Adding this to the query is straightforward: update line 13 from this:
To this:
This adjustment completely resolves the over-fetching problem, reducing the entire problem to a single request. For larger companies, pagination implementation might be necessary, but for this problem, it’s not required. Unlike HubSpot’s other APIs, GraphQL uses a points-based system for data retrieval. If you exceed 30,000 points, your request fails, necessitating optimization for substantial problems like this one. Without the simple score property and the change in line 14, this query would regularly hit the 30,000 limit for companies with 200+ contacts. However, with that one adjustment, I haven’t seen it exceed 2,000. For really massive companies with lots of contacts you'll want to implement the after parameter to page through the data.
In conclusion, we've managed to reduce a problem that initially required 2627 requests down to just one. That's what we call optimization!
