
This article was authored by a member of the HubSpot developer community, Derek Hawkins.
SEO professionals, developers, and website admins often work together to maximize the highest ROI using the least time-intensive efforts. One such impact comes from the simple yet elusive task of backend metadata optimization—specifically, the contextual structured data.
For those who need a quick refresher, structured data is contextual content around your web page that is developed so that search engines can easily parse and understand it. The implementation of schema can lead to rich snippets/dynamic media being paired with your listing on Google’s search engine results page. Appearing in a rich snippet on Google results leads to increased engagement with your organic search results. While that all sounds great in theory, marketing teams regularly highlight implementation and maintenance of schema as challenges they face.
Let’s find a solution for just this problem.
In this article, we will outline a framework for automating the development and deployment of the article schema onto blog posts. Keep in mind, though, that by making alterations to the base script, we can generate a consistent stream of various structured data types across a wide array of page types.
Why Not Use a Plug-In?
In exchange for ease of access, leveraging a third-party plug-in for schema implementation often comes with issues:
- Plug-ins that have unnecessary subscription costs that simultaneously have little to no human support or documentation
- Third-party applications you would have to loop in multiple players in building the integration. ROI of taking marketing ops and dev time on schema is an uphill battle
- Universally no support for non-standard Schema types (a nice-to-have but not a need-to-have)
For small organizations, led by a lean marketing team in which the SEO/Website Manager is acting without internal developer support, a plug-in is a good option. However, if you are scaling a site that is especially content-heavy, need a simple method for dynamic generation of schema types that works agnostic of page layout, or are just looking for an initial framework that can be expanded upon to include additional schema types in a Hubspot environment, using the CMS API for automated schema development and deployment is for you.
What about a Module?
A module also works, and it provides a scalable solution for schema implementation. You could argue that the logistics of working within multiple web properties with different page construction would require module edits (as opposed to a one-stop deployment via running the script). But at the end of the day, there are a million different ways to build a bridge, and this framework is one of those many ways.
Establishing the Framework
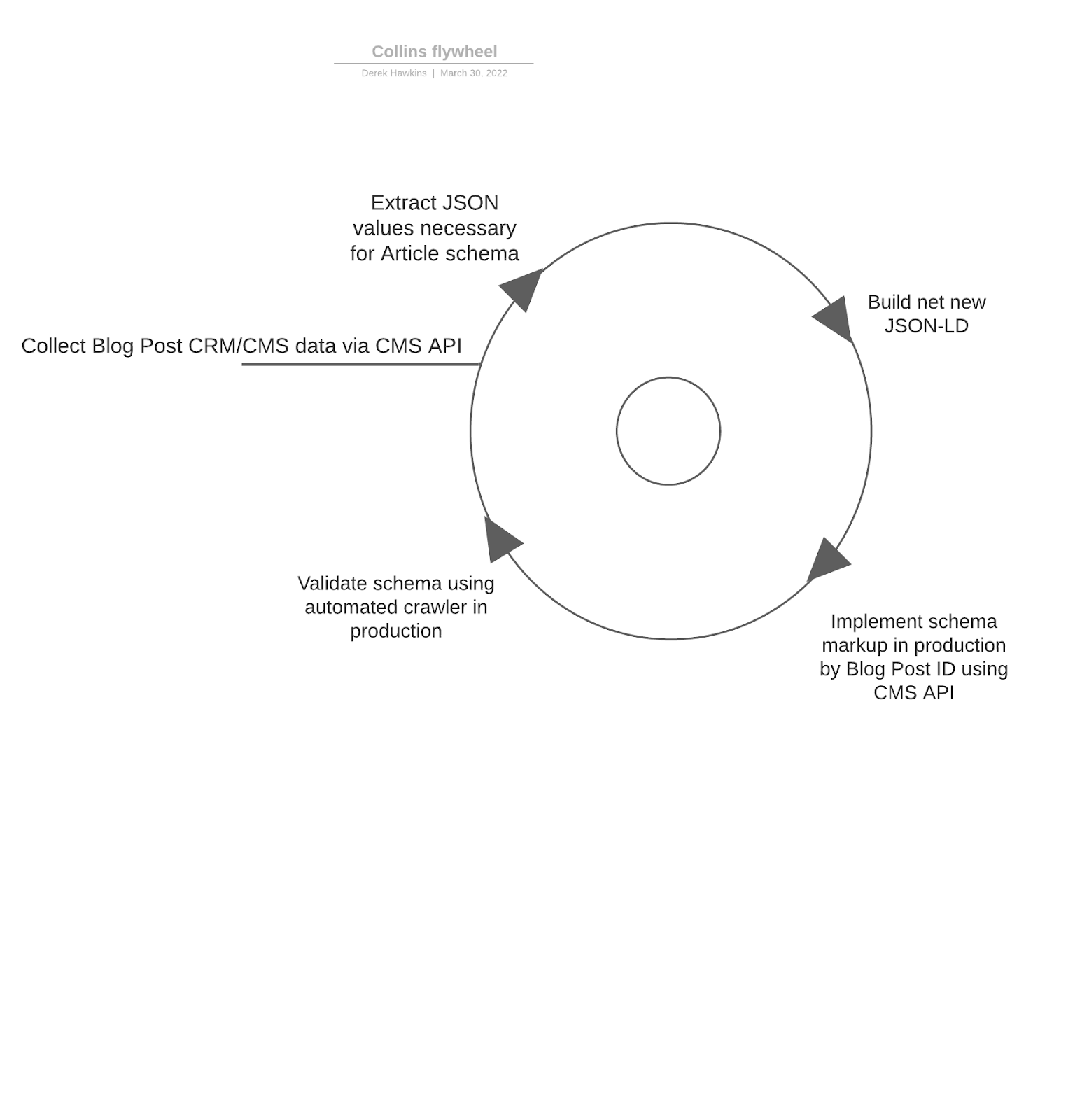
We want to create a cyclical framework for data gathering, generation, implementation, and monitoring. The diagram below illustrates the “always-on” nature which will allow for this.
Getting Started
To start, you will need the following libraries in Python:
- Hubspot: The official Hubspot Python API SDK
- Genson: A JSON schema building library
- A few core essentials that usually come packaged with any IDE in Python (Pandas, JSON, Requests, time)
Pulling the Right Data
There are a few different options for pulling out data, either directly from Hubspot or via API call. In our case, we will be pulling all of the information we need from the Hubspot API, including all public blog posts, their correlating IDs, and the information we need to build out the Article schema.
If you have never used the Hubspot API, you can get your API key by following these directions and brushing up on the basics in the documentation.
Rather than using the Hubspot API SDK for this call, we will call the Blog Post API endpoint using requests for ease of access. Because of the 100-post limit, the Hubspot Blog Post API has, we will loop over iterations of 100 until we collect every blog post on our site. In this instance, we are working with a site with approximately 1,000 blog posts.
As we go through each iteration, we will be parsing the JSON response for relevant information for our schema, including the article title, author, description, publish date, modification date, and featured image. We will store our elements in a dictionary, pass that to a list, and build a DataFrame. At the end of the loop, we will contact all our articles into a single DataFrame.
Building the Article Schema
We will be leveraging a framework I’ve used in the past to build structured data in Python. The function below uses similar elements to a function I’ve built in the past.
While you pull most of what we need via the Hubspot API, you will still want to manually incorporate the additional elements you’ll need for the Article schema to be valid.
With the data all in one place and the tools to build the schema outlined, you can iterate over our DataFrame and build the schema in a new column. You will use an f-string to make sure we have the JSON-LD <script> tag in place prior to adding to the post.
Implementation
Now that we have the schema built out, we can inject the schema directly into the HTML head of our blog post. Using the Hubspot API wrapper, we can simplify the authentication necessary to make the POST request. We’ll take the id we pulled from our initial Hubspot API call and our newly built schema and iterate over the entire DataFrame. I have added a sleep timer to ensure that the loop doesn’t timeout due to Hubspot API rate limits.
Validation
For quality assurance purposes, you’ll want to make sure the script has successfully pushed valid structured data onto your page. For this, you can close the automated loop using a third-party crawler to crawl the site.
An excellent option is Screaming Frog, an industry-recognized crawler that you can configure to run a crawl after deployment. Setting up a configured crontab file (or an .exe if you are using Windows) and running in Python allows you to collect structured data from the site, store the results in a SQL database or BigQuery instance, and match valid values back to your blog posts.
Note that this can also all be done manually via Screaming Frog as well. This typically depends on the scale of your automation efforts in parallel to the scale in which your site is deploying and changing content around.
Always-On Push
If your site has an exceptionally high content velocity or is constantly A/B testing page tags or descriptions, you can set the script to a scheduler to have it fire off on a daily basis.
A simple way of packaging this script is by running the script as a .py file with Windows Task Scheduler for Windows or a crontab on Mac. More tech-savvy marketing teams can run a scheduler using AWS Lambda (though this can sometimes feel like taking a jackhammer to a nail, it’s nice to have a method that can run agnostic of a specific machine).
Conclusion
With that, you’ll be all set! The Article schema will be live on-site and ready to validate using your preferred toolset. The implementation example above also has additional uses for site owners looking to bulk upload recommendations given by internal or external SEO resources.
Overall, this process is a great option if you want to ensure speedy implementation of quick wins but you’re pressed for time and short on resources.
