HubDB
 Marketing Hub
Marketing Hub
- Enterprise
 Content Hub
Content Hub
- Professional or Enterprise
HubDB est un outil qui vous permet de créer des tableaux pour stocker des données dans des lignes, des colonnes et des cellules, un peu comme dans une feuille de calcul. Vous pouvez personnaliser les colonnes, les lignes et les autres paramètres d'un tableau HubDB en fonction de vos besoins. Par exemple, vous pouvez utiliser un tableau HubDB pour :
- stocker les commentaires d'un mécanisme externe et les récupérer ultérieurement ;
- stocker des données structurées que vous pouvez utiliser pour créer des pages CMS dynamiques (CMS Hub Pro et Entreprise uniquement) ;
- stocker les données à utiliser dans un e-mail programmable (Marketing Hub Entreprise uniquement).
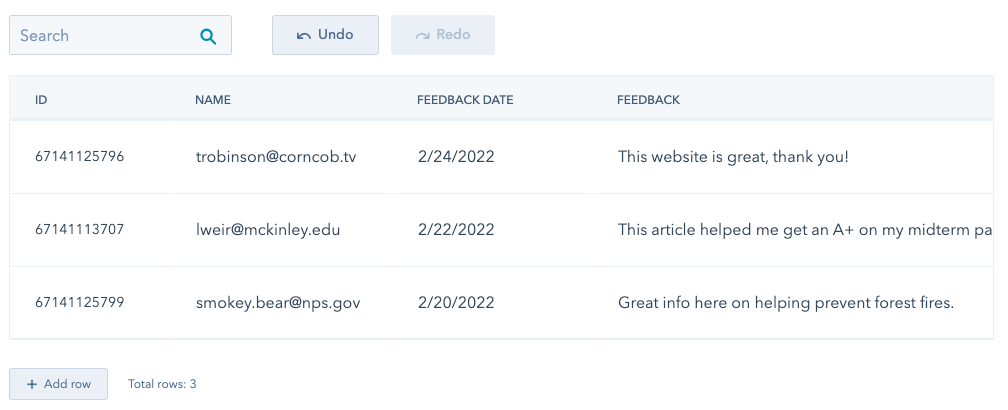 Les tableaux HubDB sont accessibles à la fois dans HubSpot et via l'API HubDB, et vous pouvez récupérer les données d'un tableau de plusieurs manières, en fonction de votre cas d'utilisation. Pour obtenir des données d'un tableau HubDB, vous pouvez :
Les tableaux HubDB sont accessibles à la fois dans HubSpot et via l'API HubDB, et vous pouvez récupérer les données d'un tableau de plusieurs manières, en fonction de votre cas d'utilisation. Pour obtenir des données d'un tableau HubDB, vous pouvez :
- interroger les données en externe via l'API HubDB ;
- utiliser les balises HubL de HubSpot pour transférer les données dans le CMS en tant que contenu structuré ;
- utiliser l'API HubDB avec des fonctions sans serveur pour offrir une expérience d'application web interactive.
Remarque :
- Pour utiliser les données HubDB dans les pages, vous avez besoin de CMS Hub Pro ou Entreprise.
- Pour utiliser les données HubDB dans des e-mails programmables, vous avez besoin de Marketing Hub Entreprise.
- La publication, la modification et la visualisation de tableaux existants nécessitent des autorisations HubDB. La création, le clonage, la suppression et la modification des paramètres d'un tableau HubDB nécessitent les autorisations Paramètres du tableau HubDB.
Un tableau HubDB se compose de lignes, de colonnes et de cellules, comme une feuille de calcul.
- Tableaux : un tableau est un arrangement bidimensionnel de lignes et de colonnes. Lorsqu'un tableau est créé, il se voit attribuer un ID globalement unique que vous pouvez utiliser lorsque vous avez besoin de spécifier un tableau dans HubL ou via l'API.
- Lignes : les lignes sont des tranches horizontales d'un tableau. Dans une application de feuille de calcul, les lignes sont représentées par des chiffres, en commençant par 1. Chaque ligne du tableau se voit attribuer un identifiant unique lors de sa création. Chaque ligne d'un tableau comprend des colonnes par défaut :
| Colonne | Description |
|---|---|
hs_id
| Un ID numérique unique, attribué automatiquement pour cette ligne. |
hs_created_at
| Un horodatage de la date de création de cette ligne. |
hs_path
| Avec des pages dynamiques, cette chaîne est le dernier segment du chemin d'accès de l'URL de la page. |
hs_name
| Avec des pages dynamiques, il s'agit du titre de la page. |
Remarque : Les colonnes de la zone de texte enrichi dans HubDB sont limitées à 65 000 caractères. Pour en savoir plus, consultez l'annonce de changement.
- Colonnes : Les colonnes sont des tranches verticales d'un tableau. Chaque colonne a un type, qui est utilisé pour stocker des types de données. Un tableau peut inclure autant de colonnes que vous le souhaitez, et chacune se voit attribuer un ID unique au niveau global lors de la création. L'ID de colonne commence à la valeur
1, mais n'est pas nécessairement séquentiel et ne peut pas être réutilisé. Les types de colonnes comprennent :- Texte
- Texte enrichi
- URL
- Image
- select
- Sélection multiple
- Date
- Date et heure
- Nombre
- Devise
- case à cocher
- Emplacement (longitude, latitude)
- ID étranger
- Vidéo
- Cellules : Les cellules stockent les valeurs à l'intersection d'une ligne et d'une colonne. Les cellules peuvent être lues ou mises à jour individuellement ou en tant que partie d'une ligne. Définir la valeur d'une cellule sur
nulléquivaut à supprimer la valeur de la cellule.
Tenez compte des limites techniques suivantes de HubDB :
- Limites de compte :
- 1 000 tableaux HubDB par compte
- 1 million de lignes HubDB par compte
- Limites de tableau :
- 250 colonnes par tableau
- 10 000 lignes par tableau HubDB
- 700 caractères par nom de tableau
- 700 caractères par libellé de tableau
- Limites de colonne :
- 65 000 caractères par colonne de texte enrichi
- 10 000 caractères par colonne de texte
- 700 caractères par nom de colonne
- 700 caractères par libellé
- 300 caractères par description de colonne
- 700 caractères par option sélectionnable dans une colonne
- Limites de page :
- 10 appels à la fonction HubL
hubdb_table_rowspar page CMS - 10 pages dynamiques utilisant le même tableau HubDB
- Les HubDB avec des pages dynamiques activées doivent avoir des chemins en minuscules afin que les URL de ces pages puissent être insensibles à la casse.
- 10 appels à la fonction HubL
Vous pouvez créer des tableaux HubDB via l'interface utilisateur de HubSpot ou l'API HubDB.
Tous les nouveaux tableaux créés ont le statut de brouillon. Ils ne peuvent pas être utilisés pour sortir des données via HubL ou l'API tant que vous n'avez pas publié le tableau. Lors de la création d'un tableau, vous pouvez également gérer ses paramètres, tels que l'autorisation d'accès à l'API publique et si ses données seront utilisées pour créer des pages dynamiques.
Les tableaux HubDB peuvent être joints à l'aide du type de colonne ID étranger, qui vous permet de restituer les données combinées à partir de plusieurs tableaux. Cela peut être utile lorsque certaines données peuvent être partagées entre plusieurs magasins de données, ce qui permet un tableau de données centralisé de ces informations, qui peut ensuite être consulté dans plusieurs autres magasins de données de tableaux HubDB.
Découvrez ci-dessous comment joindre des tableaux HubDB.
- Dans votre compte HubSpot, accédez à Marketing > Fichiers et modèles > HubDB.
- Localisez le tableau auquel vous souhaitez joindre un tableau, cliquez sur le menu déroulant Actions, puis sélectionnez Modifier.
- En haut à droite, cliquez sur Modifier, puis sélectionnez Ajouter une colonne.
- Saisissez un libellé et un nom pour la nouvelle colonne.
- Cliquez sur le menu déroulant Type de colonne et sélectionnez ID étranger.
- Cliquez sur le menu déroulant Sélectionner un tableau et sélectionnez le tableau que vous souhaitez joindre à votre tableau actuel.
- Cliquez sur le menu déroulant Sélectionner une colonne, puis sélectionnez la colonne dans le tableau à joindre que vous avez sélectionnée pour être visible dans le champ ID étranger.
- Cliquez sur Ajouter une colonne.
Remarque : La valeur que vous avez choisie pour Sélectionner une colonne indique uniquement la valeur de colonne que vous voyez dans le champ ID étranger de l'interface utilisateur HubDB. Toutes les colonnes du tableau sont disponibles lors de la restitution des tableaux HubDB joints.
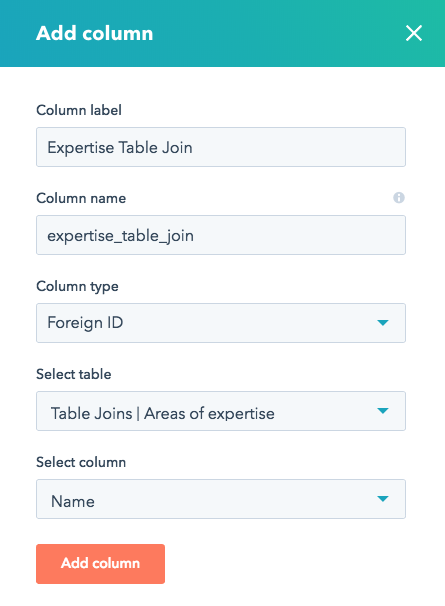
Maintenant que vous avez une colonne ID étranger, vous aurez un champ de colonne à sélection multiple sur chaque ligne de votre tableau HubDB, ce qui vous permettra de sélectionner les lignes d'un tableau étranger.
Le champ Sélectionner une colonne que vous avez choisi sera utilisé dans ce champ à sélection multiple pour identifier la ligne que vous sélectionnez dans le tableau étranger. Dans l'exemple ci-dessous, les valeurs à sélection multiple pour le champ Expertise table join sont les valeurs disponibles dans la colonne Nom du tableau HubDB étranger.
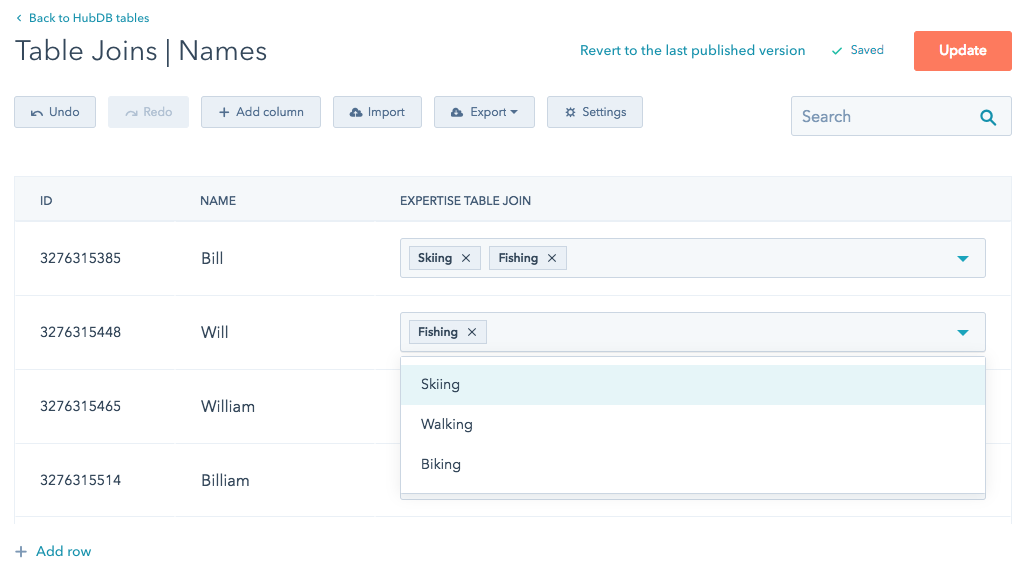
Remarque : Il est recommandé de modifier le champ Sélectionner une colonne de votre colonne ID étranger et de simplement mettre à jour les valeurs de la colonne qui s'affichera dans l'interface utilisateur HubDB.
Toutes les données de ligne d'un tableau étranger sont accessibles via HubL pour le rendu, pas seulement le champ Sélectionner une colonne. Les données de ligne étrangère HubDB sont accessibles via une boucle imbriquée, bouclant toutes les lignes étrangères associées à une ligne individuelle.
{% for row in hubdb_table_rows(tableId, filterQuery) %}
the name for row {{ row.hs_id }} is {{ row.name }}
{% for foreign_row in row.foreign_table %}
the name for foreign row {{ foreign_row.hs_id }} is {{ foreign_row.name }}
{% endfor %}
{% endfor %}En utilisant HubL, vous pouvez extraire des données HubDB pour les utiliser en tant que contenu structuré sur les pages de site web. Découvrez comment récupérer des données de tableau, de ligne et de colonne à l'aide de HubL.
Pour lister les lignes d'un tableau, utilisez la fonction HubL hubdb_table_rows(). Vous pouvez accéder à un tableau via son ID ou son nom. Il est recommandé de référencer un tableau HubDB par son nom, car cela peut faciliter la portabilité du code entre les comptes HubSpot. Le nom de tableau immuable est défini lors de la création d'un nouveau tableau et peut être retrouvé à tout moment en sélectionnant Actions > Gérer les paramètres dans l'éditeur de tableau. L'ID d'un tableau peut être trouvé dans la barre d'adresse de l'éditeur de tableau ou dans le tableau de bord des tableaux HubDB sous la colonne ID.

Voici un exemple d'utilisation de hubdb_table_rows() pour récupérer des données.
Remarque : Par défaut, 1 000 lignes au maximum sont renvoyées. Pour récupérer plus de lignes, spécifiez une limit dans la demande de fonction. Par exemple :
hudb_table_rows (12345, "random()&limit=1500").
<filterQuery> utilise la même syntaxe que l'API HTTP. Par exemple, hubdb_table_rows(123, "employees__gt=10&orderBy=count") renvoie une liste de lignes où la colonne « employees » est supérieure à 10, ordonnée selon la colonne « count ». Une liste complète des paramètres facultatifs <filterQuery> est disponible ici.
Au lieu d'utiliser plusieurs requêtes de lignes avec différents paramètres <filterQuery>, vous devez effectuer une seule requête et utiliser les filtres selectattr() ou rejectattr() pour filtrer vos lignes :
Pour obtenir une seule ligne, utilisez la fonction HubL hubdb_table_row().
Les noms des colonnes intégrées et personnalisées sont insensibles à la casse. HS_ID fonctionnera de la même manière que hs_id.
| Attribut | Description |
|---|---|
row.hs_id
| L'identifiant unique au niveau mondial pour cette ligne. |
row.hs_path
| Lorsque vous utilisez des pages dynamiques, cette chaîne est la valeur de la colonne Chemin de page et le dernier segment du chemin d'accès de l'URL. |
row.hs_name
| Lorsque vous utilisez des pages dynamiques, cette chaîne est la valeur de la colonne Titre de la page pour la ligne. |
row.hs_created_at
| Horodatage Unix de la date de création de la ligne. |
row.hs_child_table_id
| Lorsque vous utilisez des pages dynamiques, il s'agit de l'ID de l'autre tableau qui alimente les données de la ligne. |
row.column_name
| Obtenez la valeur de la colonne personnalisée par le nom de la colonne. |
row["column name"]
| Obtenez la valeur de la colonne personnalisée par le nom de la colonne. |
Pour obtenir les métadonnées d'un tableau, notamment son nom, ses colonnes, sa dernière mise à jour, etc., utilisez la fonction hubdb_table().
Les attributs listés ci-dessous sont en référence à la variable à laquelle la fonction hubdb_table() a été attribuée dans le code ci-dessus. Votre variable peut être différente.
Remarque : Il est recommandé de l'attribuer à une variable pour une utilisation plus facile. Si vous ne voulez pas faire cela, vous pouvez utiliser{{ hubdb_table(<tableId>).attribute }}
| Attribut | Description |
|---|---|
table_info.id
| L'ID du tableau. |
table_info.name
| Le nom du tableau. |
table_info.columns
| Une liste d'informations sur les colonnes. Vous pouvez utiliser une boucle for pour itérer à travers les informations disponibles dans cet attribut. |
table_info.created_at
| L'horodatage de la date de création de la table. |
table_info.published_at
| L'horodatage de la date de publication de ce tableau. |
table_info.updated_at
| L'horodatage de la dernière mise à jour de ce tableau. |
table_info.row_count
| Le nombre de lignes dans le tableau. |
La fonction hubdb_table_column peut être utilisée pour obtenir des informations sur une colonne du tableau telles que son libellé, son type et ses options.
Les attributs listés ci-dessous sont en référence à la variable à laquelle la fonction hubdb_table_column() a été attribuée dans le code ci-dessus. Votre variable peut être différente.
Remarque : Il est recommandé de l'attribuer à une variable pour une utilisation plus facile. Si vous ne voulez pas faire cela, vous pouvez utiliser{{ hubdb_table_column(<tableId>,<columnId or column name>).attribute }}
| Attribut | Description |
|---|---|
table_info.id
| L'ID de la colonne. |
table_info.name
| Le nom de la colonne. |
table_info.label
| Le libellé à utiliser pour la colonne. |
table_info.type
| Le type de cette colonne. |
table_info.options
| Pour les colonnes de type select, il s'agit d'un mappage de |
table_info.foreignIds
| Pour les colonnes de type foreignId, une liste de foreignIds (avec les propriétés |
| Méthode | Description |
|---|---|
getOptionByName("<option name")
| Pour certains types de colonnes, vous pouvez obtenir des informations sur les options par leur nom. |
Le type de colonne richtext fonctionne de la même manière que le champ de texte enrichi pour les modules.
Les données sont stockées en HTML et l'interface utilisateur HubDB fournit une interface d'édition de texte. Cependant, lors de la modification d'un tableau HubDB via l'interface utilisateur de HubSpot, vous ne pouvez pas modifier directement le code source. Cela permet d'éviter les situations où un utilisateur non expert pourrait saisir un code HTML non valide, ce qui élimine tout problème indésirable d'apparence ou de fonctionnalité de votre site. Pour les situations où vous avez besoin d'un code d'intégration ou d'un code HTML plus personnalisé, vous pouvez utiliser la fonction d'intégration de l'éditeur de texte enrichi pour placer votre code personnalisé.
Merci d'avoir partagé votre avis.